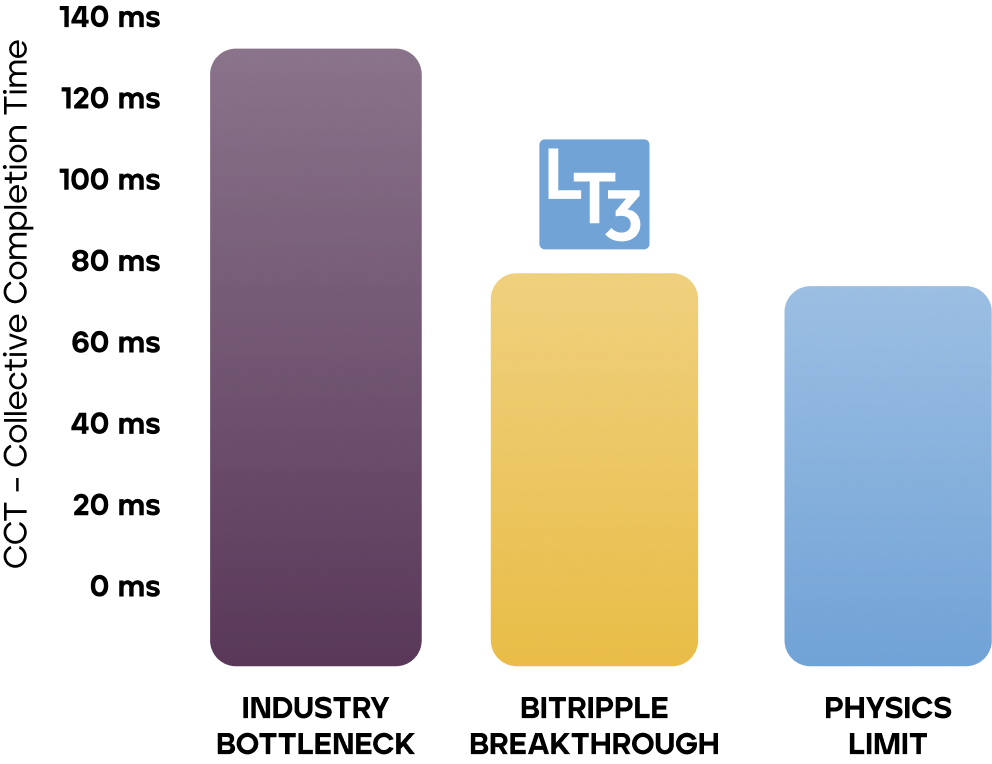How BitRipple LT3™ Removes Network Barriers to Fast
Training
AI model training clusters depend on fast, synchronized communication between GPUs. But protocols
like RoCEv2 struggle with packet loss, flow collisions, and congestion -leading to idle GPUs and
slower time-to-train.
No need for expensive and complex hardware solutions for scheduling to avoid contention,
LT3™ uses a real time erasure-coding resiliency protocol at the source. Combined with spraying
packets granularly across all available paths, and decoding out-of-order without
retransmissions, LT3™ achieves breakthrough results: lower collective completion time (CCT),
higher GPU utilization, and faster model convergence.
Using this approach, we have achieved within 2% of the lower theoretical bound for collective
completion time (CCT).